Replay an Archived Stream Data in Azure Stream Analytics – Design and Implement a Data Stream Processing Solution

- Log in to the Azure portal at https://portal.azure.com➢ navigate to the Azure Stream Analytics job you created in Exercise 3.17➢ select Input from the navigation menu ➢ select the + Add Stream Input drop‐down menu ➢ select Blob Sorage/ADLS Gen2 ➢ provide an input alias name (I used archive) ➢ select Connection String from the Authentication Mode drop‐down list box ➢ select the ADLS container where you stored the output in Exercise 7.9➢ and then enter the path to the file into the Path Pattern text box, perhaps like the following. Note that the filename is shortened for brevity and is not the actual filename of the output from Exercise 7.9.
EMEA/brainjammer/in/2022/09/09/10/0_bf325906d_1.json - The configuration should resemble Figure 7.46. Click the Save button.
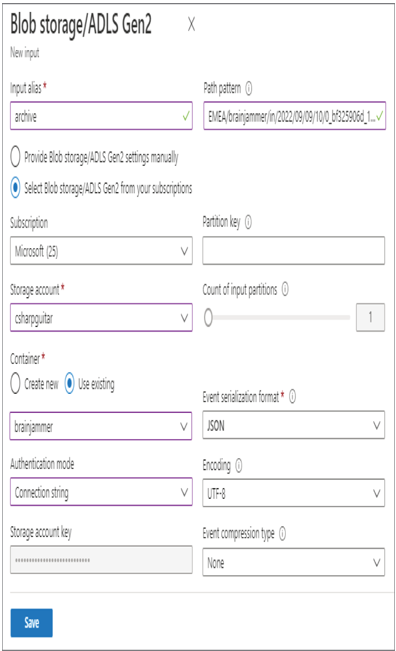
FIGURE 7.46 Configurating an archive input alias
- Select Query from the navigation menu ➢ enter the following query into the query window ➢ click the Save Query button ➢ and then start the job. The query is available in the StreamAnalyticsQuery.txt file located in the Chapter07/Ch07Ex10 directory on GitHub.
SELECT Scenario, ReadingDate, ALPHA, BETA_H, BETA_L, GAMMA, THETA
INTO ADLS
FROM archive
- Wait until the job has started ➢ navigate to the ADLS container and location you configured for the archive input alias in step 1 ➢ download the 0_bf325906d_1.json file from the Chapter07/Ch07Ex10 directory on GitHub ➢ upload that file to the ADLS container ➢ and then navigate to the location configured for your ADLS Output alias. A duplicate of the file is present, as shown in Figure 7.47.
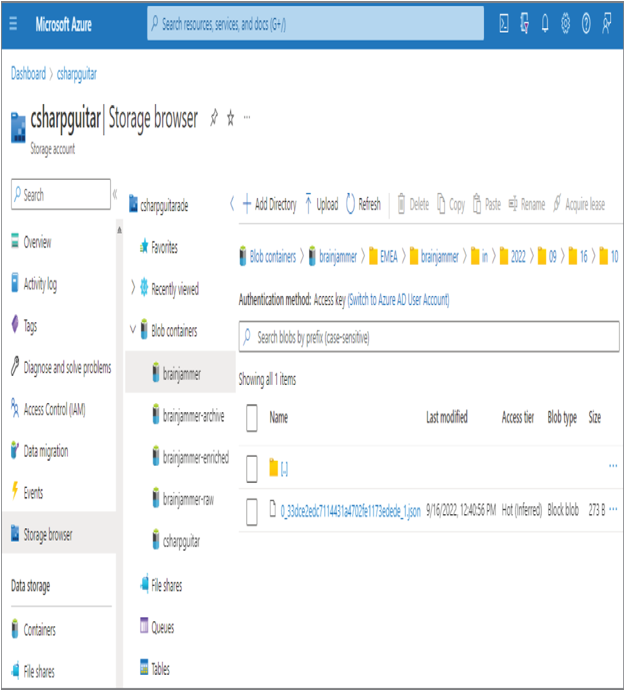
FIGURE 7.47 Archive replay data result
- Stop the Azure Stream Analytics job.
Exercise 7.10 illustrates how a file generated by the output of a data stream can be replayed and stored on a targeted datastore. You may be wondering why something like this would be needed. Testing new features, populating testing environments with data, or taking a backup of the data are a few reasons for archiving and replaying data streams. One additional reason to replay data is due to downstream systems not receiving the output. The reason for missing data might be an outage on the downstream system or a timing issue. If an outage happened downstream and data was missing from that store, it is likely easy to understand why: the data is missing because the datastore was not available to receive the data.
The timing issue that can result in missing data can be caused by the timestamp assigned to the data file. The timestamp for a data file stored in an ADLS container is in an attribute named BlobLastModifiedUtcTime. Consider the action you took in step 4 of Exercise 7.10, where you uploaded a new file into the location you configured as the input for your Azure Stream Analytics job. Nothing happened when you initially started the job, for example, at 12:33 PM. This is because files that already exist in that location will not be processed, because their timestamp is earlier than the start time of the Azure Stream Analytics job. When you start a job with a Job Output Start Time of Now (refer to Figure 7.18), only files that arrive after the time are processed. Once you added the file with a timestamp after the job had already been started, for example, 12:40 PM, it got processed.
The same issue could exist for downstream systems, in that the data file could arrive at a datastore but the processor is experiencing an outage of some kind. When it starts back up and is online, it may be configured to start processing files only from the current time forward, which would mean the files received during the downtime will not be processed. In some cases, it might be better and safer to replay the data stream instead of reconfiguring and restarting all the downstream systems to process data received while having availability problems. Adding the file in step 4 is not the only approach for getting the timestamp updated to the current time. If you open the file, make a small change that will not have any impact on downstream processing, and then save it, the timestamp is updated, and it will be processed. Perform Exercise 7.10 again but instead of uploading the 0_bf325906d_1.json file, make a small change to the file already in that directory and notice that it is processed and passed into the output alias ADLS container.
Leave a Reply