Design and Configure Exception Handling – Design and Implement a Data Stream Processing Solution

An exception is an unexpected event that occurs in the execution of your program code or query. Exceptions do happen and need to be managed because, in most cases, unmanaged exceptions stop the execution of your code at that point. This can leave your data and your program in an undesirable state, which can result in further data corruption. You need to understand which kinds of known exceptions can happen in your Azure Stream Analytics processing. Table 7.8 provides a list of Azure Stream Analytics exceptions.
TABLE 7.8 Azure Stream Analytics exceptions
| Exception | Description |
| InputDeserializationError | Unable to deserialize input data. |
| InputEventTimestampNotFound | Unable to retrieve a timestamp for a resource. |
| InputEventTimestampByOverValueNotFound | Cannot get the value of the TIMESTAMP BY OVER COLUMN. |
| InputEventLateBeyondThreshold | An event was sent later than the configured tolerance. |
| InputEventEarlyBeyondThreshold | An event has an arrival time earlier than the application timestamp. |
| AzureFunctionMessageSizeExceeded | The output message exceeds the size limit for Azure Functions. |
| EventHubOutputRecordExceedsSizeLimit | The record exceeds the message size limit for Event Hubs. |
| CosmosDBOutputInvalidId | The type or value of a column is invalid. |
| CosmosDBOutputInvalidIdCharacter | There is an invalid character in the document ID for the record. |
| CosmosDBOutputMissingId | The record does not contain an ID to use as a primary key. |
| CosmosDBOutputMissingIdColumn | The record is missing a document ID property. |
| CosmosDBOutputMissingPartitionKey | The record is missing the partition key property. |
| CosmosDBOutputSingleRecordTooLarge | A single record is too large to write. |
| SQLDatabaseOutputDataError | Cannot write to Azure SQL Database due to data issues. |
When you begin processing your data stream and nothing is happening, the reason is likely one of the exceptions listed in Table 7.8. There are numerous locations where you can view exceptions that get thrown during the stream processing. The first one is diagnostic logging, which is configurable from the Diagnostic Settings blade in the Azure portal. There is more on this feature in Chapter 9; however, look at Figure 7.50 to get an idea about what this looks like.
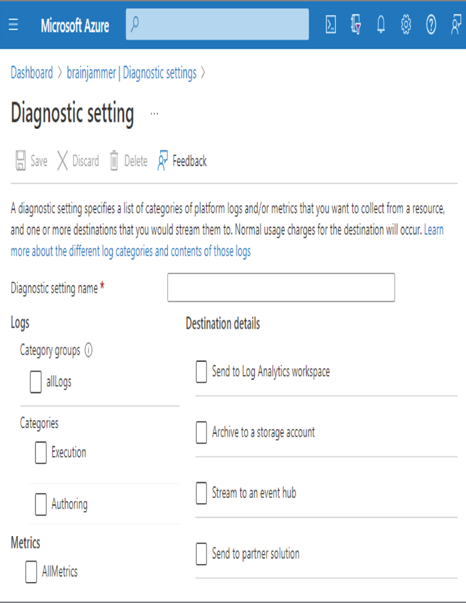
FIGURE 7.50 Azure Stream Analytics Diagnostics Setting
Notice the different categories and that logging performance metrics are also possible. The locations where you can store the logs are listed in the Destination Details column. The options are a Log Analytics workspace, a storage account, an event hub, or a partner solution, which are endpoints provided by Microsoft Azure partners. The other location to view exceptions is on the Activity Log blade, as shown in Figure 7.51.
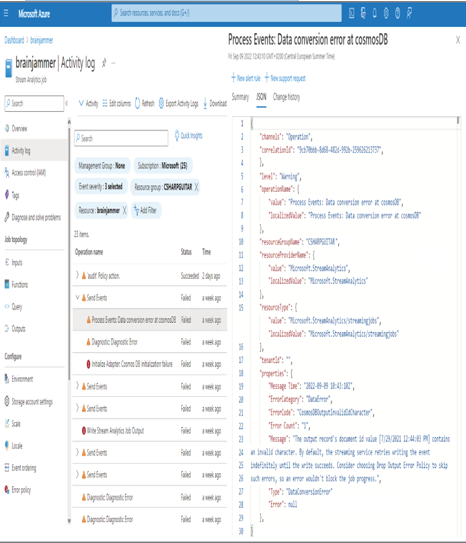
FIGURE 7.51 Azure Stream Analytics Activity log warnings and errors
Line 21 of the Send Events operation warning message shows a CosmosDBOutputInvalidIdCharacter error. After some analysis, it turns out Azure Cosmos DB does not like the timestamp used as the document ID in that format. The Azure Stream Analytics query had to be changed to get the data into the correct format so that the output could handle it. If you look back at the query for Exercise 7.9, you will notice some special handling of the ReadingDate column in the query. The reason for that query pattern was a result of the solution to this exception.
The last part of the topics necessary for designing and configuring exception handling is just that. When an exception happens, Azure Stream Analytics offers two options, Retry and Drop. Look again at Figure 7.51; there is a navigation menu option named Error Policy. On that blade there are two options, Retry and Drop. Retry is the default and means the data stream processor will retry writing the message to the output until it succeeds, indefinitely. This setting will ultimately block the output of that and any other message streaming to that point. If you experience a scenario where the data stream has stopped flowing, then there is a blockage, and you need to find and resolve the exception before it begins working again. The other option is to drop the message and not process it. If you choose this option, you need to realize that the message cannot be recovered or replayed, so it will be purged and lost.