Optimize Pipelines for Analytical or Transactional Purposes – Design and Implement a Data Stream Processing Solution

There are numerous approaches for optimizing data stream pipelines. Two such approaches are parallelization and compute resource management. You have learned that setting a partition key in the date message results in the splitting of messages across multiple nodes. By doing this your data streams are processed in parallel. You can see how this looks in Figure 7.31 and the discussion around it. Managing the compute resources available for processing the data stream will have a big impact on the speed and availability of your data to downstream consumers. As shown in Figure 7.48, the increase in the watermark delay was caused by the CPU utilization on the processor nodes reaching 100 percent.
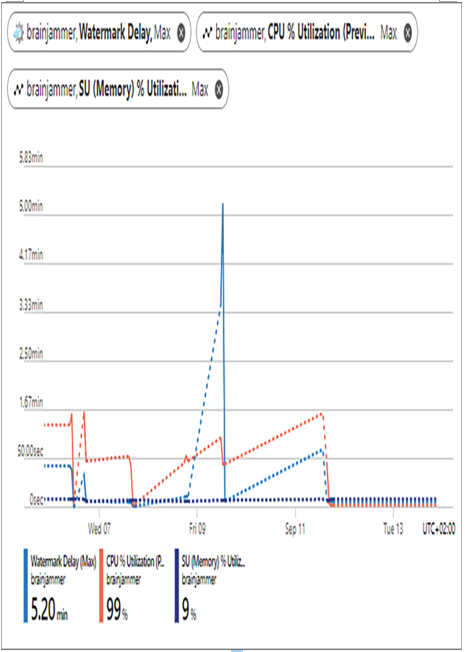
FIGURE 7.48 Azure Stream Analytics job metrics, CPU at 99 percent utilization
When the CPU is under such pressure, event messages get queued, which causes a delay in processing and providing output. Increasing the number of SUs allocated to the Azure Stream Analytics job will have a positive impact on the pipeline, making it more optimal for analytical and transactional purposes.
Scale Resources
As mentioned in the previous section, adding more resources to the Azure Stream Analytics Job will result in faster processing of the data stream. This assumes that you have noticed some processing delays and see that the current level of allocated resources is not sufficient. To increase the amount of compute power allocated to an Azure Stream Analytics job, select the Scale navigation link for the given job, as shown in Figure 7.49.
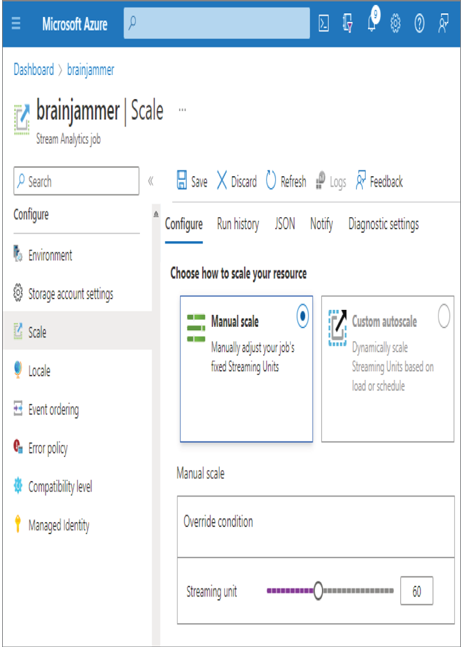
FIGURE 7.49 Azure Stream Analytics job scaling
Once compute power is allocated, when you start the job, instead of seeing 3, as shown in Figure 7.18, you will see the number described in the Manual Scale Streaming Unit configuration. In this case, the number of SUs would be 60.
Leave a Reply